Kafka General Overview for Beginners

What is Kafka and what problem does it solve?
Kafka is a distributed streaming platform that is used to build real-time data pipelines and streaming applications. It is designed to handle large volumes of data and provide high throughput.
To understand the problem that Kafka solves, let's look at an example. Suppose you place an order on Zomato and want to track the location of your delivery agent. Zomato sends the real-time location of the delivery boy every 1 second to you.
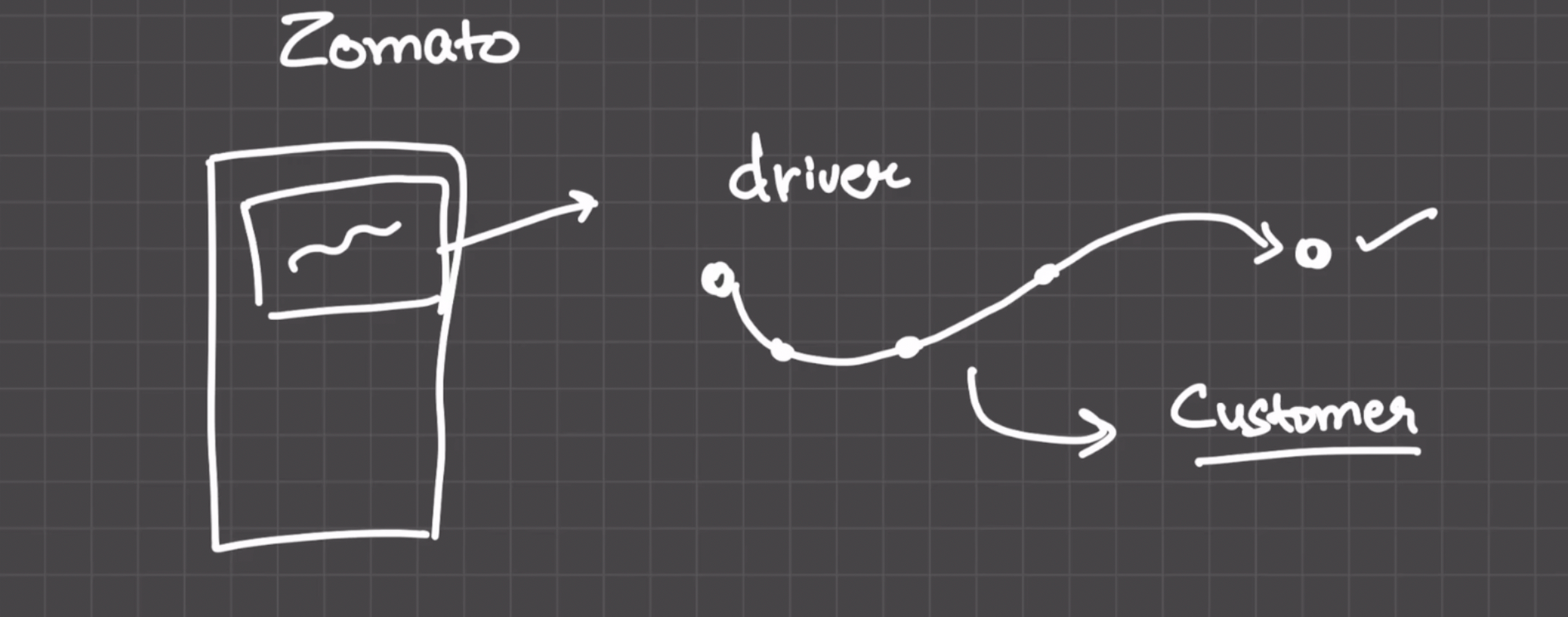
However, before sending this real-time location to its customers, Zomato saves this data on its own database present inside its own server. For every second, it performs an insert operation onto the database. If we use a traditional SQL database and try to perform 100 or 1000 insert operations into our database per second, the database would go down.
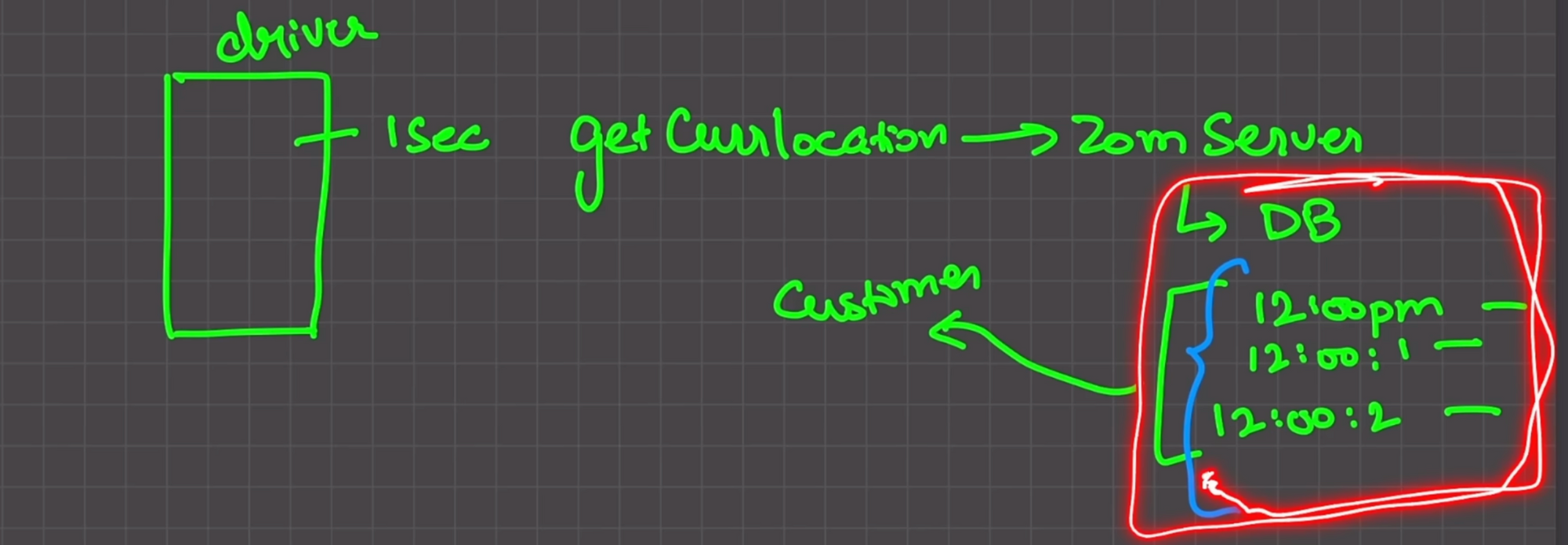
This is where Kafka comes in. One of the properties of Kafka is that it has high throughput. Throughput is measured in terms of operations performed per second, such as reading and writing at a particular time.
Exactly what do we need database or Kafka?
| Throughput | Storage | |
| Kafka | High | Low |
| Database | Low | High |
Note → Kafka allows a large amount of data to pass through but cannot hold the data for a long time.
So what conclusion we can draw is that we need to use both a database as well as Kafka together.
Million-dollar question
Let’s take the example of OLA and Uber, suppose we have 200,000 cars, each producing data every second, such as speed and location. We need to store this data in a database. We can have unprocessed raw data in Kafka and have consumers consume this data. This way, we can process large amounts of data without causing the database to go down.
We can feed unprocessed raw data into Kafka.
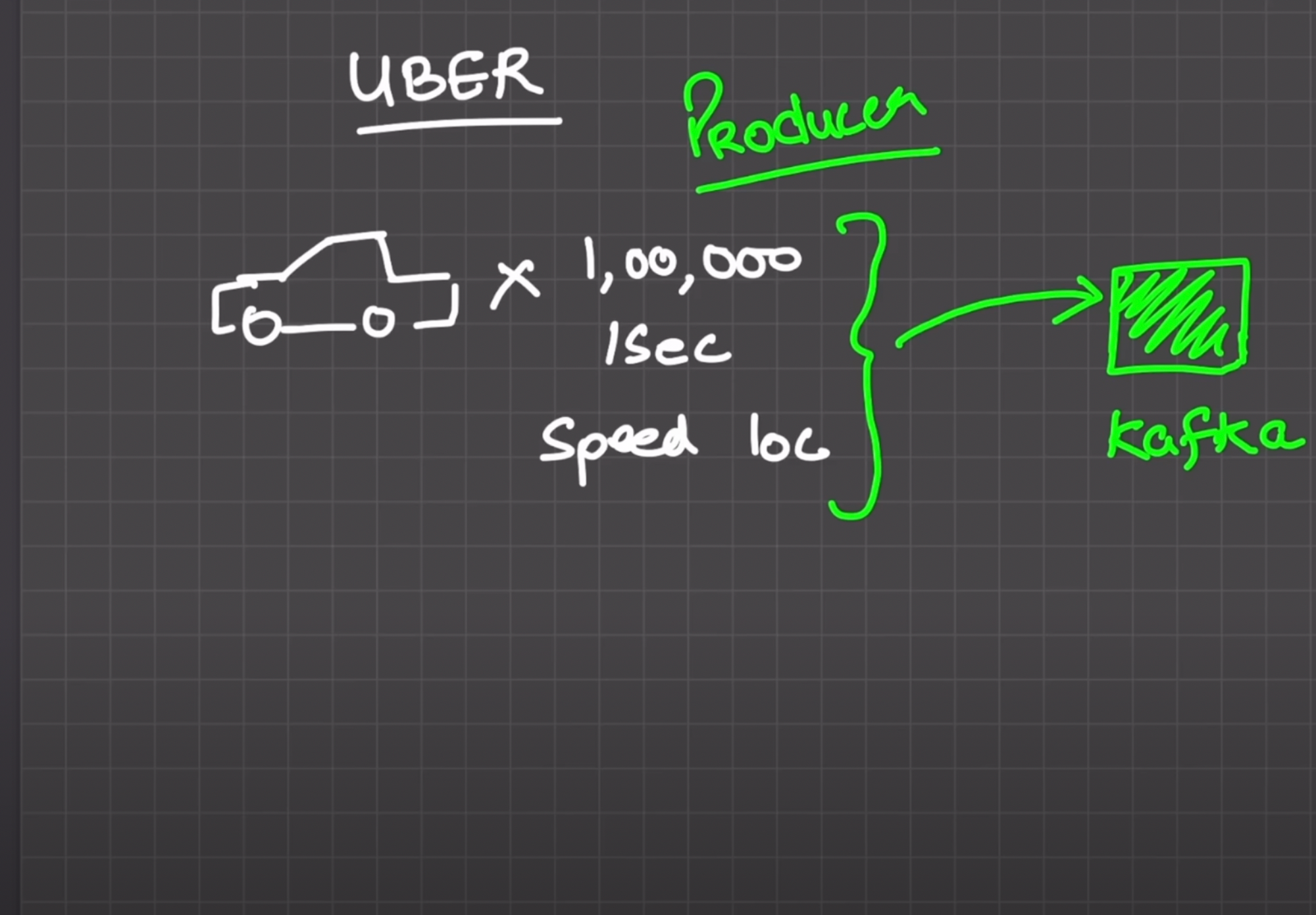
Now we have consumers as well to consume these data.
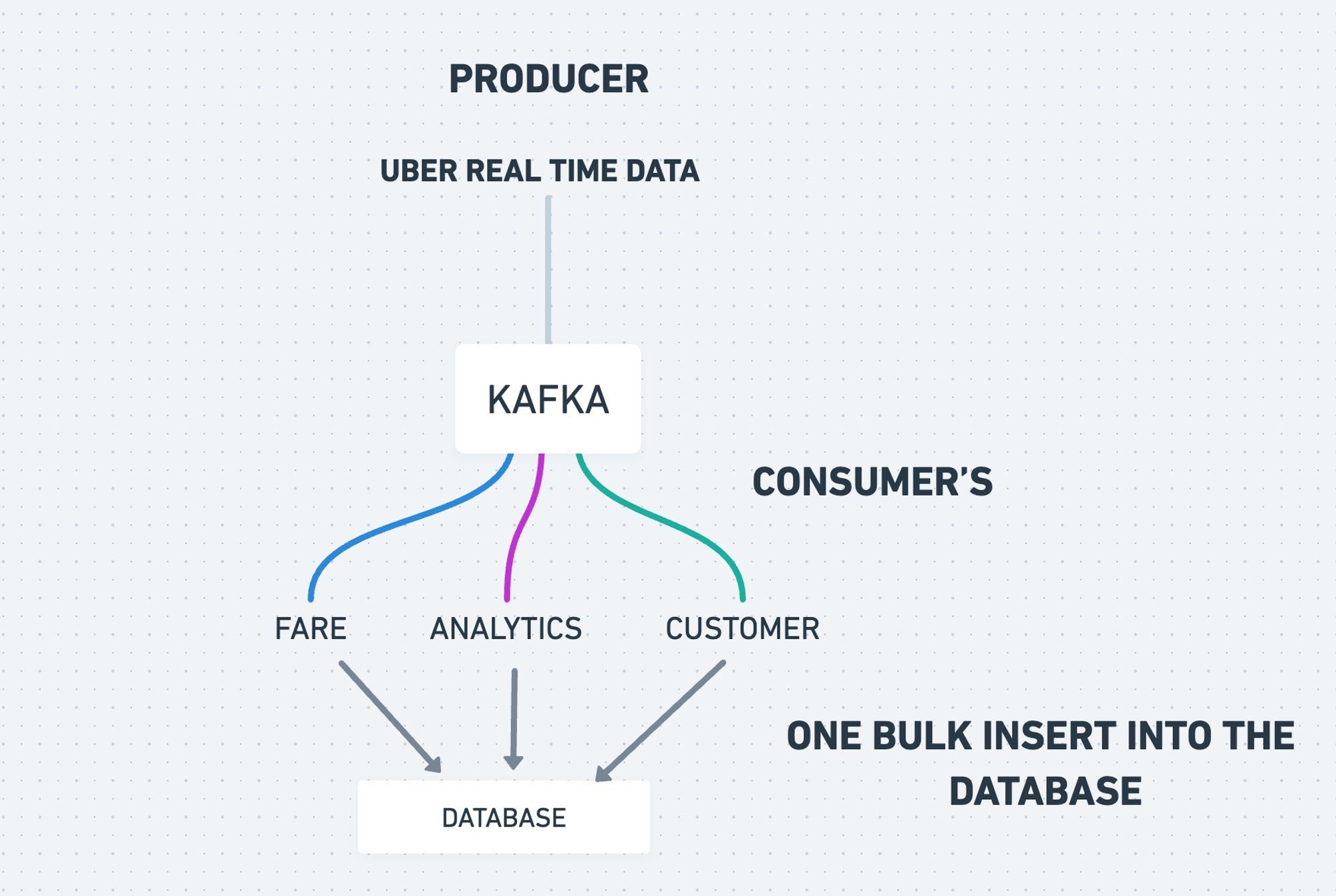
Architecture of Kafka
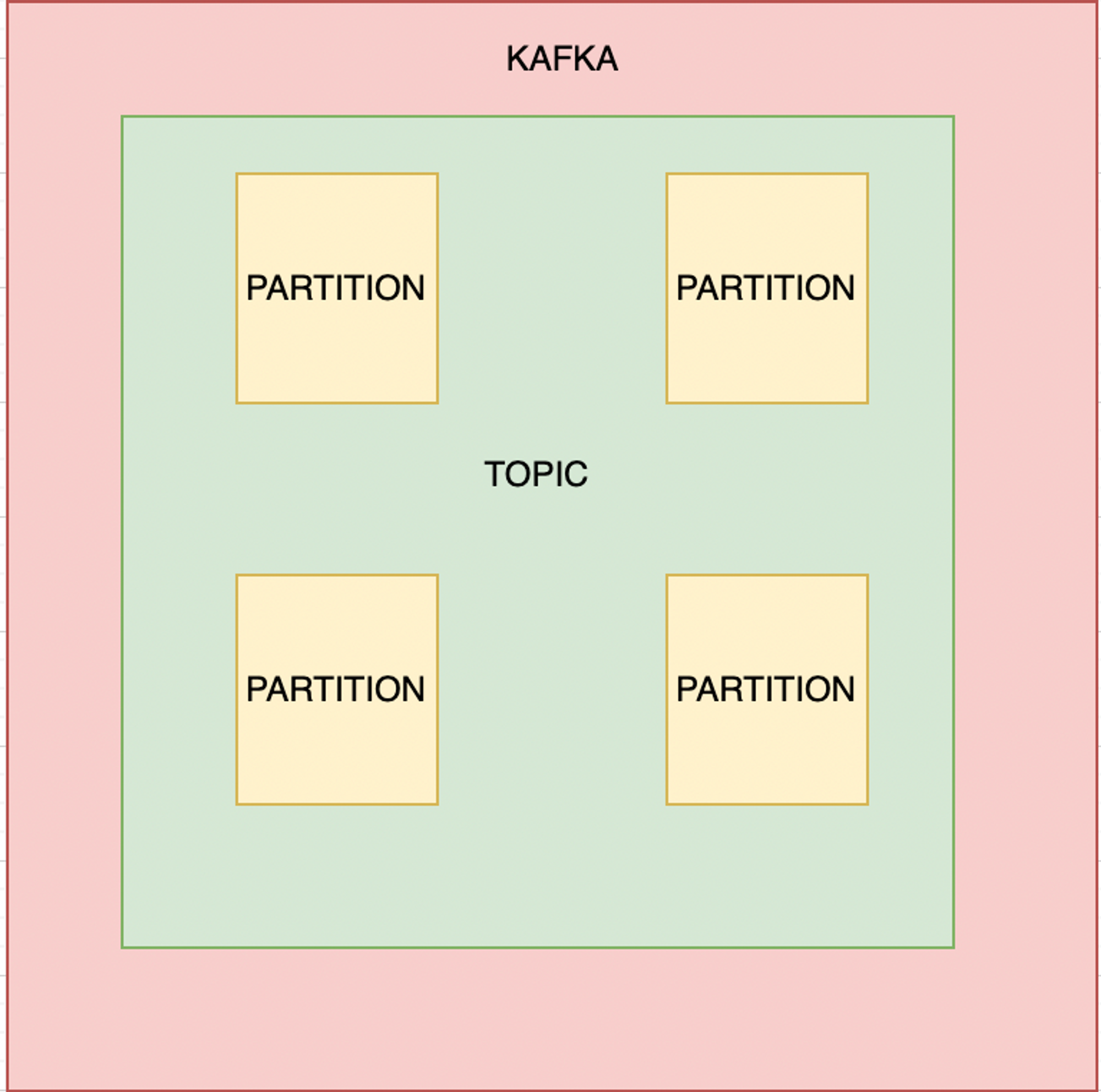
Kafka consists of four main components: producers, consumers, topics, and partitions.
Producers are responsible for producing data to Kafka. They send messages to topics, which are logical streams of data. Each message is identified by a unique key and can contain any type of data.
Consumers read data from Kafka. They subscribe to topics and receive messages from them. Consumers can be part of a consumer group, which allows them to work together to process messages more efficiently.
Topics are logical streams of data in Kafka. They can be partitioned to allow for greater throughput and parallel processing. Each message in a topic is stored in one partition, and each partition can be replicated for fault tolerance.
Partitions are the building blocks of topics in Kafka. They allow for parallel processing and provide fault tolerance by replicating data across multiple brokers.
Overall, Kafka provides a highly scalable and fault-tolerant platform for building real-time data pipelines and streaming applications.
Auto balancing in Kafka means that if we have 2 consumers and 4 partitions, each consumer will handle 2 partitions. If we have 3 consumers, each will handle 1 partition and 1 consumer will handle 2 partitions. However, if we have 5 consumers, one partition will always remain idle.
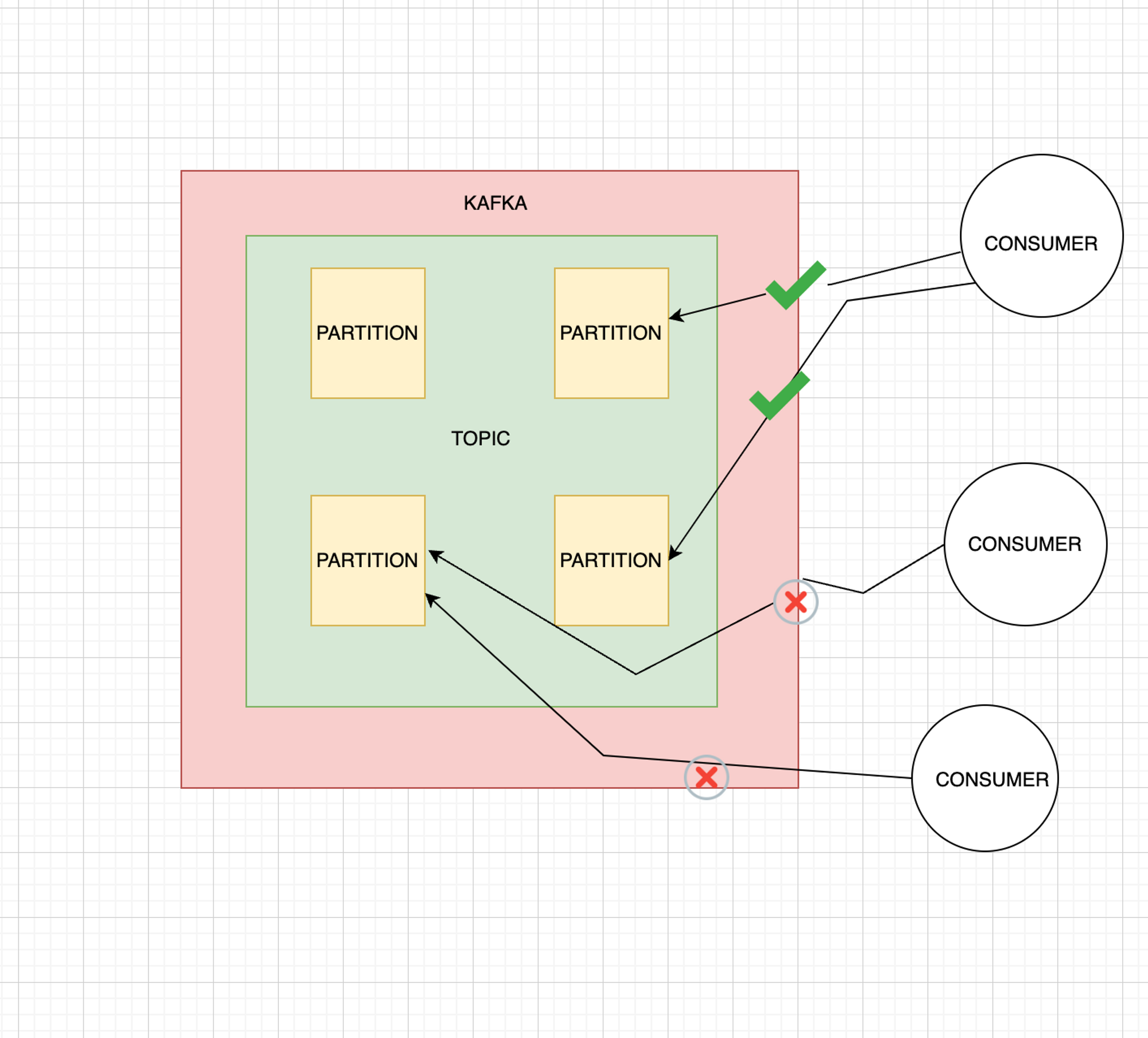
Very Important point to note →
1 consumer can consume multiple partition, but one partition can be consumed by one consumer only.
Consumer Groups
The concept of group-level balancing.
So whenever we make a consumer, it is by default placed under a group.
A bunch of consumers can form a group in order to cooperate and consume messages from a set of topics. This grouping of consumers is called a Consumer Group.
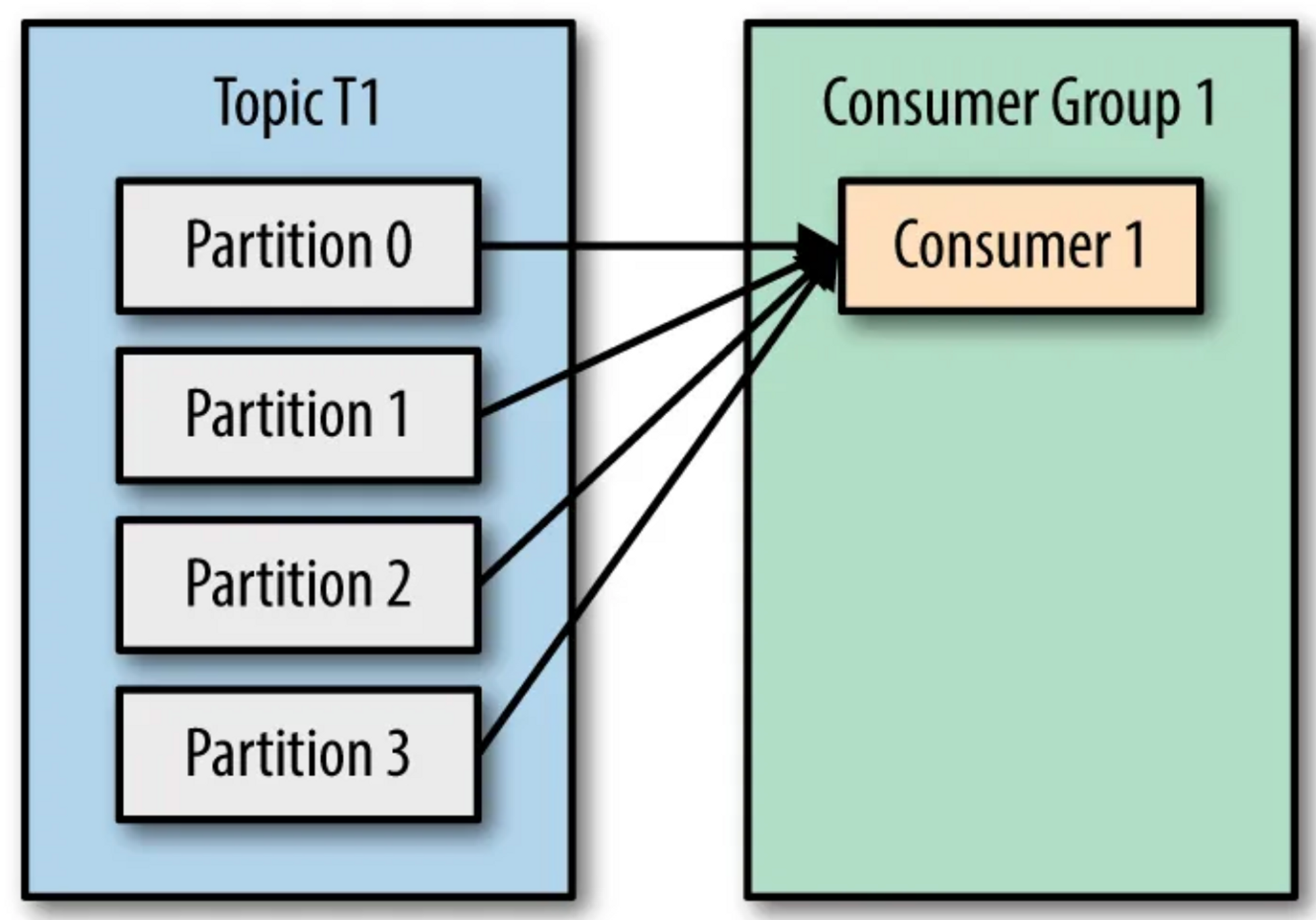
Scenario 1: Let’s say we have a topic with 4 partitions and 1 consumer group consisting of only 1 consumer. The consumer has subscribed to the TopicT1 and is assigned to consume from all the partitions. This scenario can be depicted by the picture below:
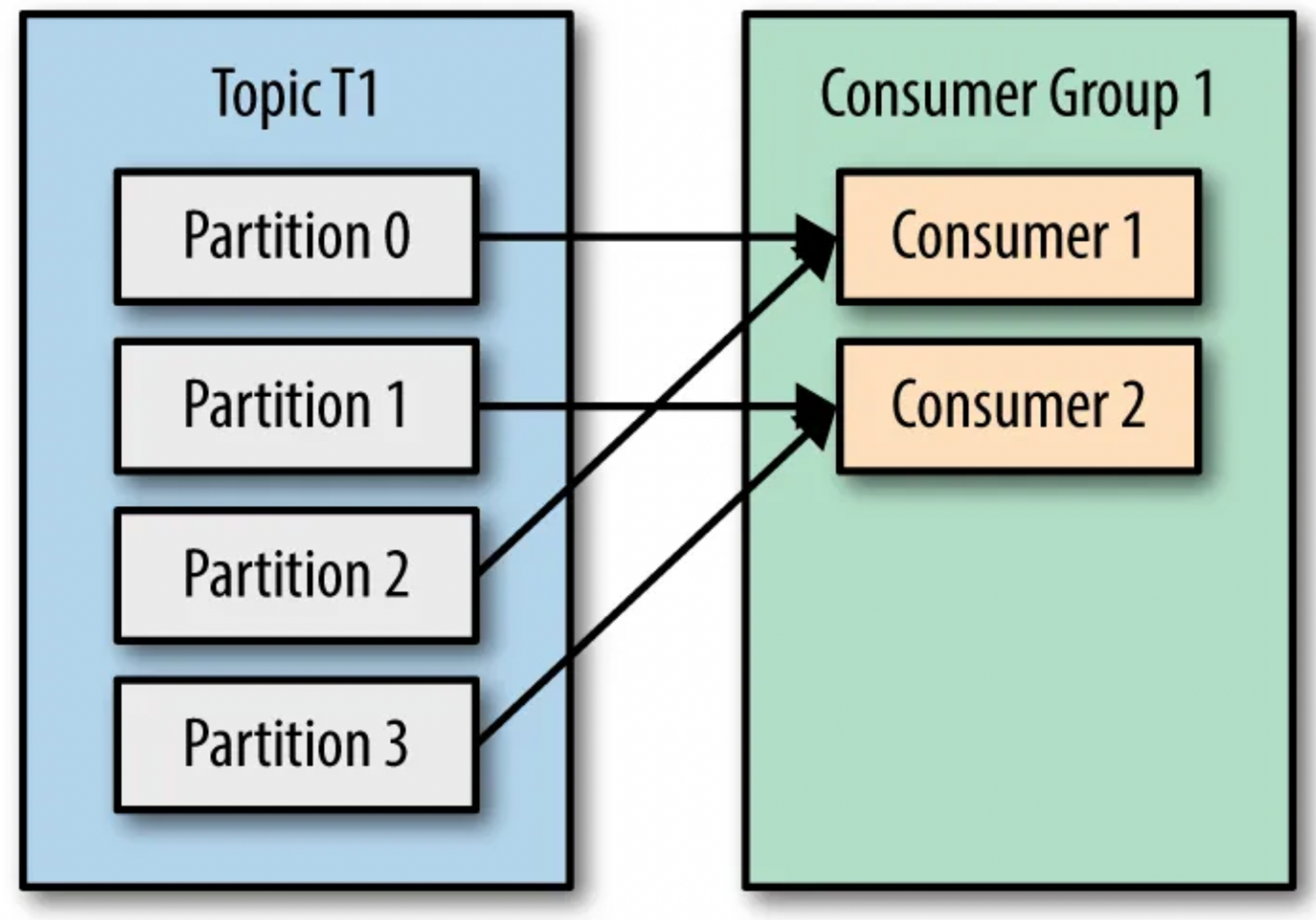
Scenario 2: Now let’s consider we have 2 consumers in our consumer group. These 2 consumers would be assigned to read from different partitions — Consumer1 assigned to read from partitions 0, 2; and Consumer2 assigned to read from partitions 1, 3.
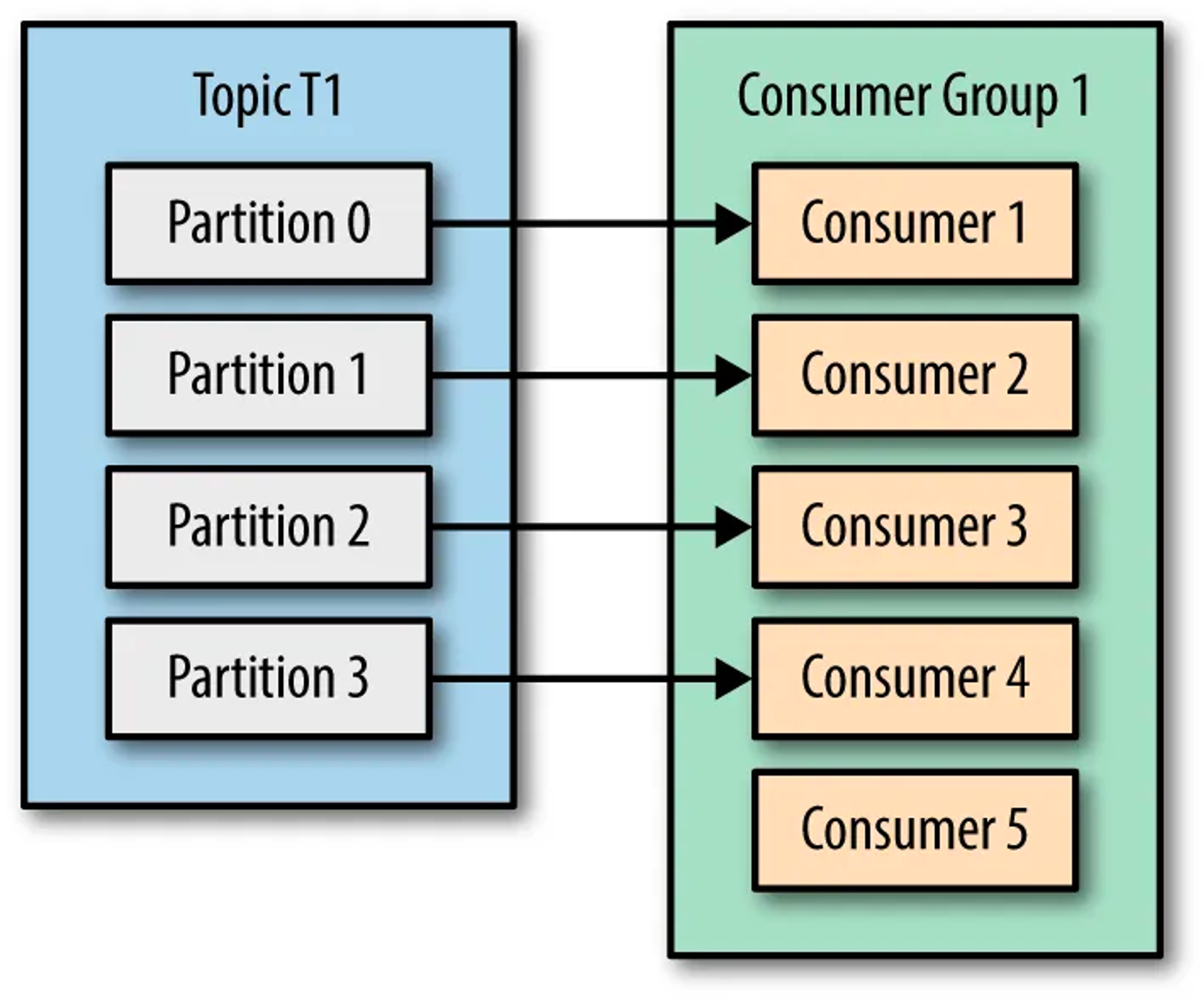
Scenario 3: Let’s say we have 5 consumers in the consumer group which is more than the number of partitions of the TopicT1, then every consumer would be assigned a single partition and the remaining consumer (Consumer5) would be left idle. This scenario can be depicted by the picture below:
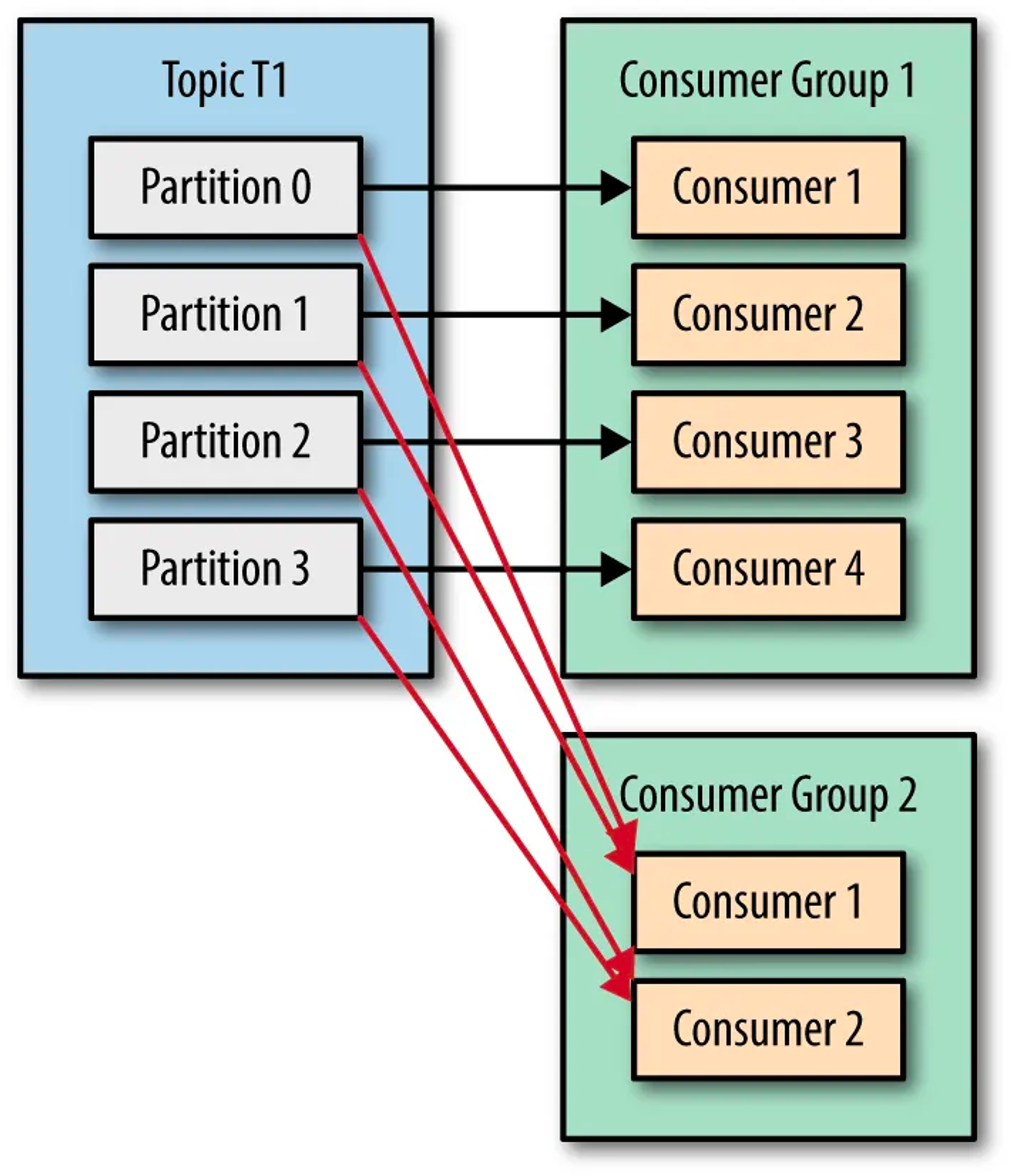
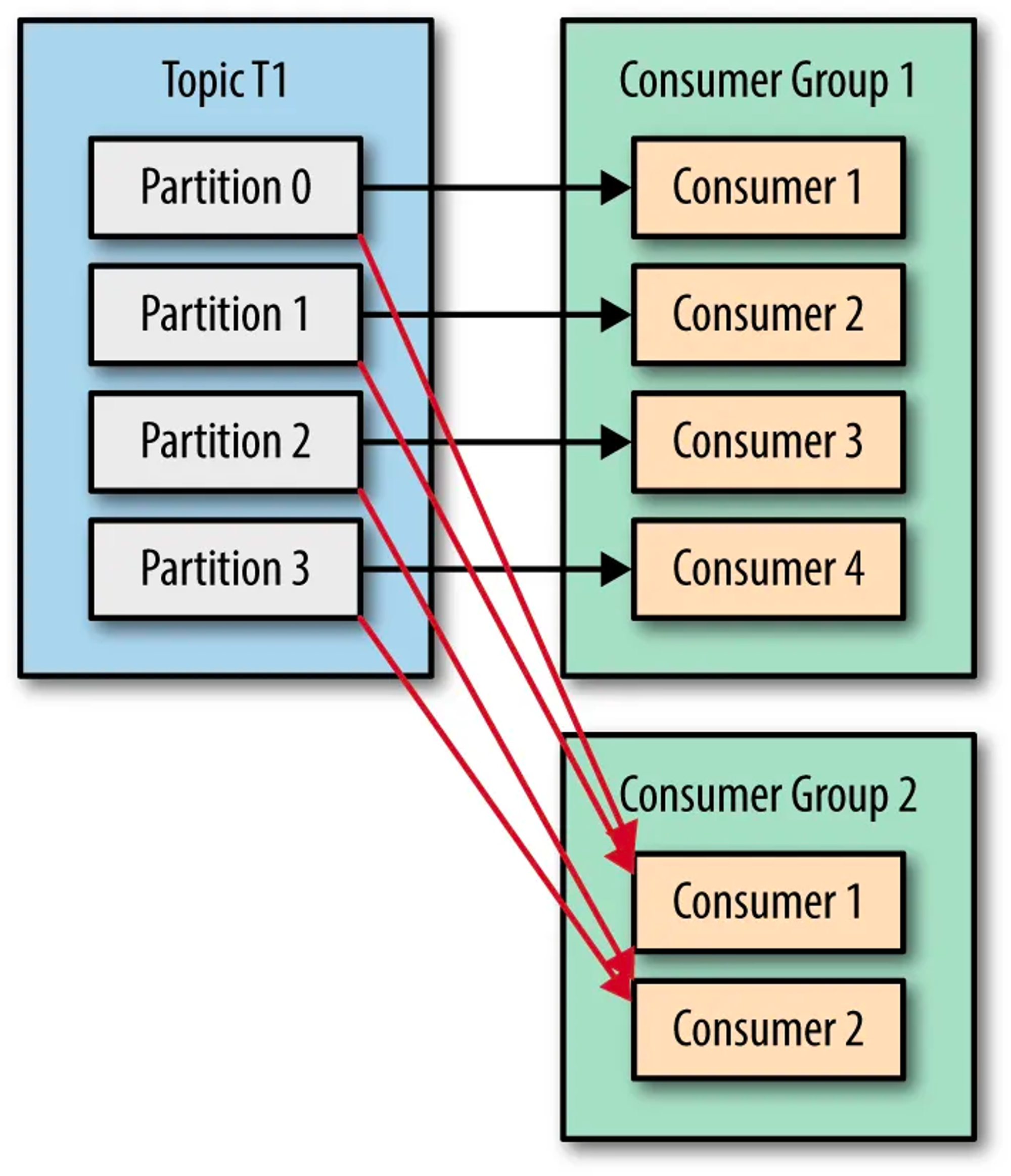
Scenario 4: If you want to assign multiple consumers to read from the same partition, then you can add these consumers to different consumer groups, and have both of these consumer groups subscribed to the TopicT1. Here, the messages from Partition0 of TopicT1 are read by Consumer1 of ConsumerGroup1 and Consumer1 of ConsumerGroup2. This scenario can be depicted by the picture below:
Kafka - Queue or Pub-Sub
Kafka claims to be both a Queue and a Pub-Sub by utilizing the concept of a consumer group.
Kafka as queue → No. of partition = No. of consumers [One on One mapping]
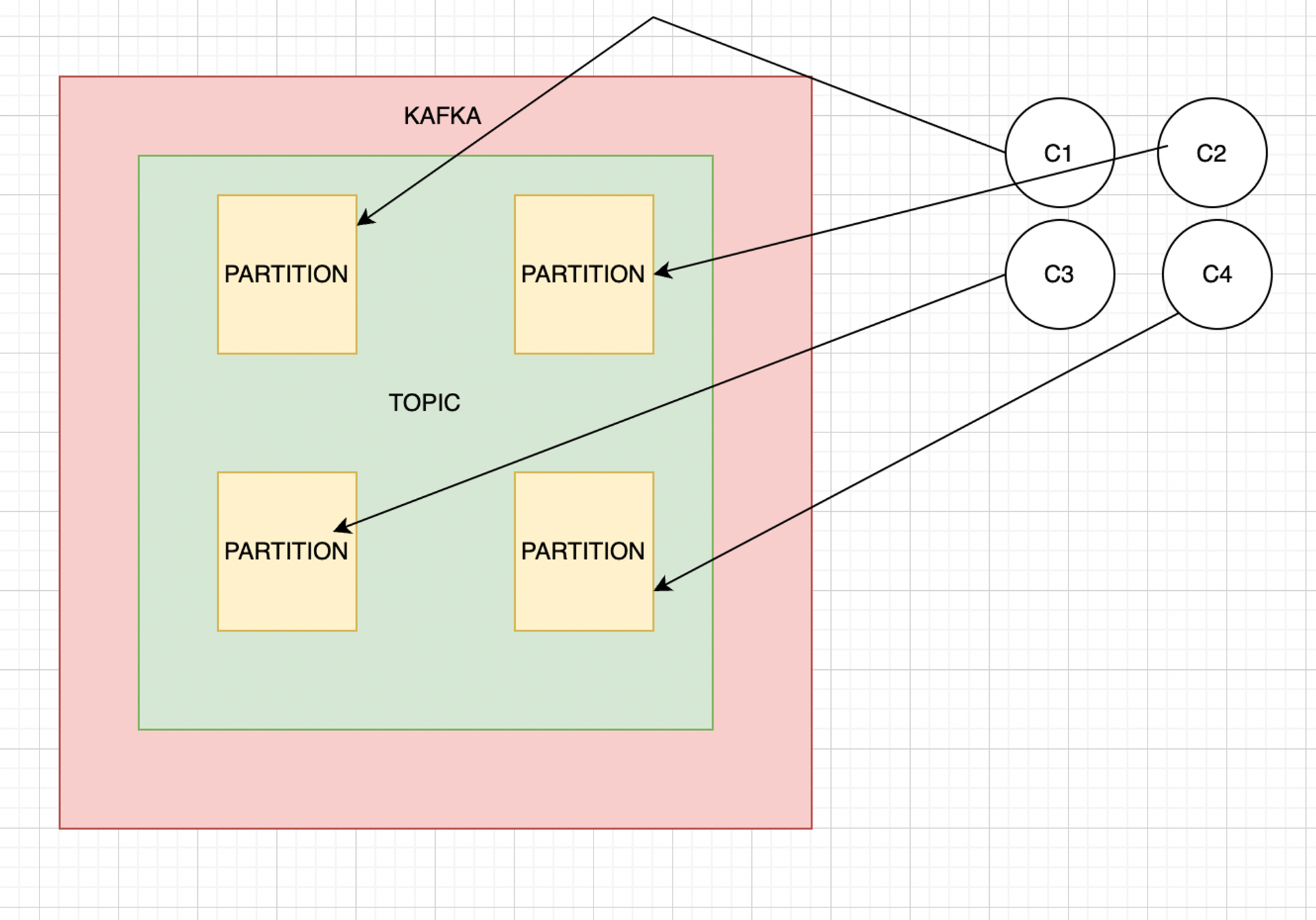
Kafka as Pub-sub
Conclusion
Kafka is widely used in various industries, such as finance, health care, and e-commerce. With its high throughput and scalability, Kafka has become an essential tool for modern data-driven applications.